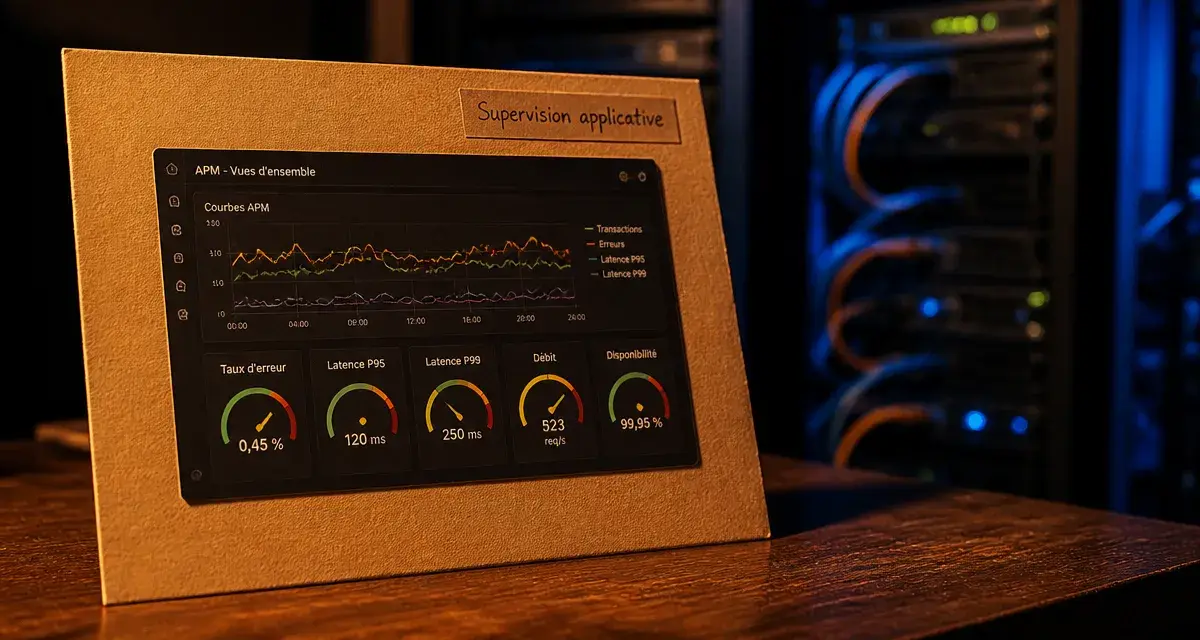
Dans un écosystème numérique où la moindre seconde de latence entraîne une perte de chiffre d’affaires, la surveillance des infrastructures ne suffit plus. Si vos serveurs sont au vert mais que vos utilisateurs ne parviennent pas à valider leur panier, votre système de monitoring est aveugle. La supervision applicative, ou APM (Application Performance Monitoring), ne se contente pas de vérifier si la machine est allumée : elle s’assure que le service rendu par l’application est fluide, rapide et fonctionnel.
Qu’est-ce que la supervision applicative et pourquoi dépasse-t-elle le monitoring classique ?
La supervision applicative est une discipline informatique qui consiste à surveiller en temps réel la santé, la performance et la disponibilité des applications logicielles. Contrairement à la supervision d’infrastructure, qui se focalise sur le matériel comme le CPU ou la mémoire vive, l’approche applicative adopte le point de vue de l’utilisateur final et du code source.
Elle permet de suivre le parcours d’une requête depuis l’interface client jusqu’à la base de données, en passant par les APIs et les microservices. L’objectif est d’identifier précisément le composant qui ralentit la chaîne de valeur.
La visibilité de bout en bout
Avec la montée en puissance des architectures cloud et des microservices, une application moderne ressemble souvent à un puzzle complexe de services interconnectés. Sans supervision applicative, lorsqu’un incident survient, les équipes techniques perdent un temps précieux à chercher l’origine du problème, ce qui alourdit le MTTR (Mean Time To Repair). La supervision applicative offre une visibilité granulaire, permettant de pointer la ligne de code défectueuse ou la requête SQL trop gourmande.
L’expérience utilisateur au cœur de la stratégie
La performance technique est une composante directe de l’expérience client. Un temps de réponse qui s’allonge de quelques millisecondes dégrade le taux de conversion ou la productivité des collaborateurs internes. La supervision applicative permet de définir des seuils d’alerte basés sur le ressenti utilisateur, garantissant ainsi le respect des engagements de service (SLA).
Les indicateurs clés de performance à surveiller absolument
Pour piloter efficacement une application, il faut sélectionner les données pertinentes. Voici les quatre piliers d’une supervision applicative réussie :
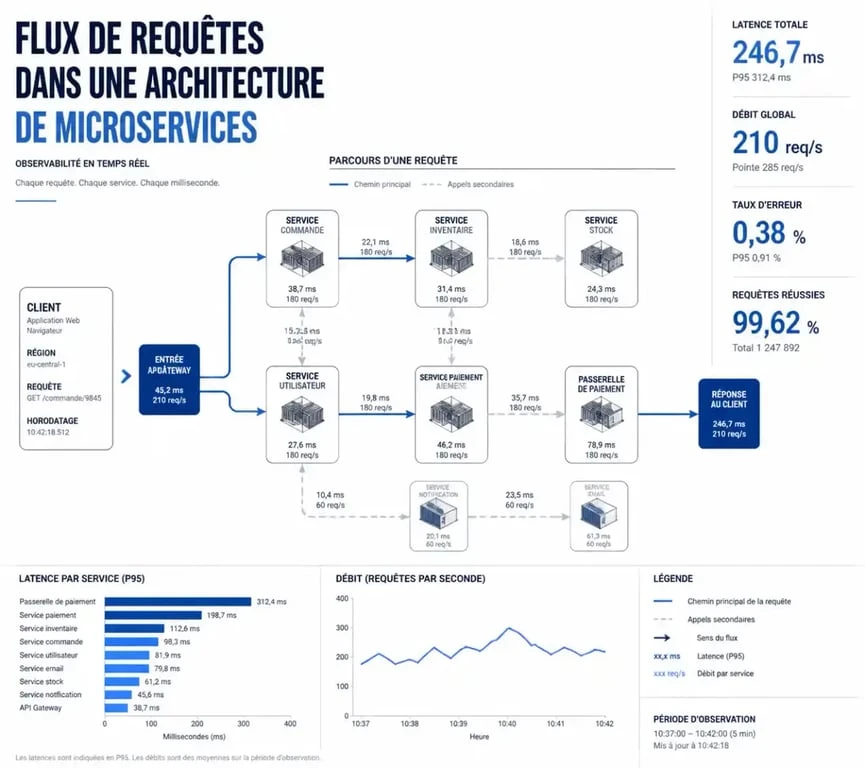
Le taux d’erreur mesure le pourcentage de requêtes qui échouent par rapport au total. Un pic soudain d’erreurs 500 signale souvent un bug de déploiement ou une dépendance externe défaillante. Le temps de réponse, ou latence, représente la durée nécessaire pour qu’une application traite une demande. Il doit être analysé par centiles (P95, P99) pour ne pas masquer les ralentissements subis par une minorité d’utilisateurs. Le débit, ou throughput, indique le nombre de requêtes traitées par seconde. Une chute brutale peut indiquer un problème réseau, tandis qu’une hausse soudaine annonce une saturation imminente. Enfin, la disponibilité, ou uptime, mesure le pourcentage de temps pendant lequel l’application est accessible et fonctionnelle.
Au-delà de ces chiffres bruts, la supervision applicative moderne intègre des concepts d’observabilité. Chaque requête utilisateur est une particule circulant à travers votre infrastructure. Si cette trajectoire ralentit, la supervision capture l’état complet du système à cet instant précis. Cette approche permet de comprendre non seulement quand le système faiblit, mais surtout pourquoi il dévie de sa trajectoire nominale, offrant une capacité de diagnostic chirurgicale inaccessible aux outils traditionnels.
Comment choisir et déployer son outil de supervision ?
Le marché des solutions APM est vaste, allant des outils open source aux plateformes SaaS. Le choix dépend de la complexité de votre stack technique et de vos ressources humaines.
| Type d’outil | Avantages | Inconvénients |
|---|---|---|
| Solutions SaaS (Datadog, Dynatrace, New Relic) | Déploiement rapide, IA intégrée, maintenance nulle. | Coût élevé, dépendance au fournisseur, stockage externe. |
| Open Source (Prometheus, Grafana, ELK) | Gratuité, personnalisation totale, souveraineté. | Configuration complexe, nécessite une expertise interne. |
| Outils Cloud (CloudWatch, Azure Monitor) | Intégration native, coût lié à l’usage. | Limité à un seul fournisseur, profondeur applicative moindre. |
Les critères de sélection essentiels
Avant de choisir, vérifiez la compatibilité de l’outil avec vos langages de programmation comme Java, Python ou Node.js, et vos environnements comme Kubernetes. La capacité de l’outil à corréler automatiquement les métriques, les logs et les traces est un critère majeur. L’ergonomie des tableaux de bord est également cruciale : ils doivent être compréhensibles par les développeurs comme par les managers métiers.
Les étapes d’une mise en œuvre réussie
Le déploiement demande de la méthode. Identifiez d’abord les applications les plus critiques pour votre activité. Installez les agents de collecte sur un environnement de pré-production pour valider l’absence d’impact sur les performances, ce qu’on appelle l’overhead. Une fois en production, définissez des paliers d’alerte intelligents : évitez le bruit inutile en ne notifiant les équipes que sur des anomalies réelles et impactantes.
Les bénéfices concrets pour l’entreprise et les équipes techniques
Investir dans la supervision applicative est une assurance contre l’indisponibilité. Les bénéfices se font sentir à plusieurs niveaux de l’organisation.
Une collaboration accrue entre Dev et Ops
En partageant une source de vérité unique, les développeurs et les administrateurs systèmes cessent de se renvoyer la balle lors d’un incident. La supervision applicative fournit des preuves tangibles, favorisant une culture DevOps où la résolution de problème prime sur la recherche de coupable.
Réduction des coûts opérationnels
La détection proactive permet de corriger des anomalies mineures avant qu’elles ne deviennent des pannes coûteuses. De plus, l’analyse précise de l’utilisation des ressources permet d’optimiser l’infrastructure et de réduire la facture cloud en supprimant le sur-provisionnement inutile.
Protection de l’image de marque
Une application indisponible devient rapidement un sujet de discussion public. La supervision applicative permet de réagir avant que les utilisateurs ne commencent à se plaindre, préservant ainsi la réputation et la confiance envers vos services numériques.
L’avenir de la supervision : vers l’AIOps et l’auto-remédiation
La supervision applicative évolue vers l’AIOps, ou l’intelligence artificielle appliquée aux opérations informatiques. L’objectif est d’utiliser le machine learning pour analyser des volumes massifs de données et détecter des signaux faibles invisibles à l’œil humain. À terme, certains systèmes seront capables d’auto-remédiation : si une instance applicative sature, l’outil pourra déclencher automatiquement le redémarrage d’un service ou l’ajout de ressources sans intervention humaine.
Adopter une stratégie de supervision applicative aujourd’hui prépare votre infrastructure à cette autonomie future, tout en garantissant dès maintenant une qualité de service irréprochable à vos utilisateurs.